目次
- 背景と目的
- 過去のシステム
- 室内シーン変遷ロギングシステム
- 関連研究
背景と目的

室内環境、例えば、研究室や社内オフィスといった場所は多くの人が出入りするので、誰が物を[持ち込んだ/持ち去った]のか特定することは困難です。さらに、室内の映像が保存されていたとしても、長時間の記録映像から目的のシーンを探し出すのは労力を要する上に見逃しの問題もはらんでいます。
そこで、このような大量の映像データをシステムが自動整理して効率よく保存しておき、ユーザは必要最低限の指示を行うだけで目的のシーンを検索できれば非常に便利です。
室内監視班では、監視映像下に起こる「物体の持ち込み/持ち去り/移動」といったイベントを自動的に検知・整理しておき、実シーン中で直接ジェスチャによって物体や空間を指し示すことで「これを持ってきたのは誰?」等と直観的に問い合わせできる検索操作システムを開発しています。
過去のシステム
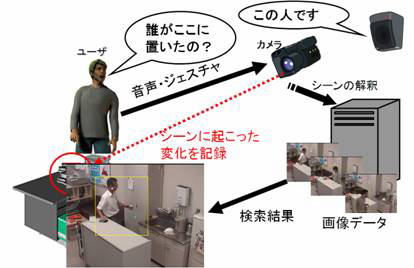
この室内監視の研究は長期間にわたって開発されているものです。
上図は、過去に用いられていた室内監視の概要図です。
室内シーン変遷ロギングシステム
システム概要
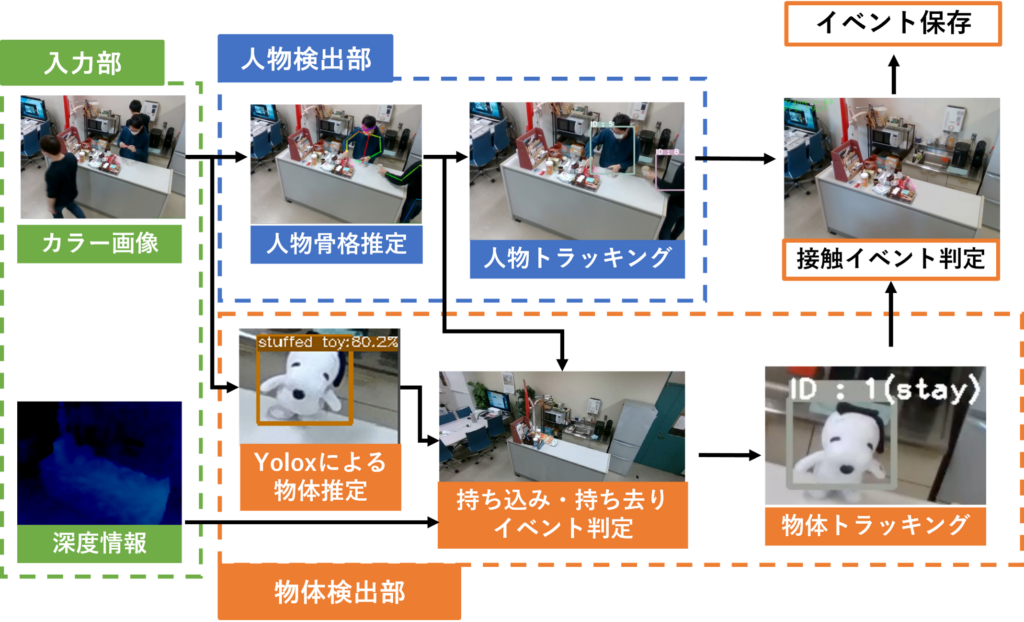
現在のシステムの概要は上図のようになっており、主な機能は以下の4つに分けられます。
1. 入力部
2. 人物検出部
3. 物体検出部
4. イベント検知基幹システム部
以下にそれぞれの機能について説明します。
1. 入力部


入力部では、室内の情報をカメラデバイスを用いて取得し、その情報を処理サーバーへ提供しています。
提供している情報は、上図のようなカラー画像と深度情報です。
2. 人物検出部

人物検出部では、入力部から提供された情報を受け取り、人物の検出を行っています。人物の検出には外部ライブラリのOpenPoseという深層学習モデルを導入しています。このOpenPoseによる骨格推定の様子が上図です。

また、OpenPoseで取得した骨格情報から人物をトラッキングすることができます。人物にIDとBounding Boxでトラッキングをした様子が上図です。
3. 物体検出部

物体検出部では、入力部から提供された情報を受け取り、物体の検出を行っています。物体の検出にはYOLO11を用いており、上図のようにカラー画像から物体を検出し、物体名とBounding Boxで範囲を推定しています。また, 画像中の各ピクセル単位での領域マスクの結果も出力しています。
4. イベント検知基幹システム部
イベント検知基幹システムでは人物検出部、物体検出部で検出した人物と物体の情報を元に「持ち込んだ」「触れた」「持ち去った」といった人物と物体間に起きたイベントを検知しています。イベントを検知するとイベント情報を画面に表示したり、情報を保存し蓄積したりしています。動画では、上部でイベントを検知しており、下部で物体のトラッキングの様子を示しています。
関連研究
1. 物体の位置姿勢を考慮した片付けの想起
研究室や会社のオフィスといったローカルな空間では,独自の習慣や文化が形成され,その一つに片付けがあります.「何が」「どこに」「どのように」配置するかはその空間に属する人間や物体によって決定するため,前もって学習させたモデルでは対応することが困難です.そこで,設置したカメラから得られる情報を用いて随時学習させることで解決できるのではないかと考えました.
本研究では,カメラから得られる情報をもとに複数の物体の位置姿勢を学習し,予測するモデルの構築に取り組みました.
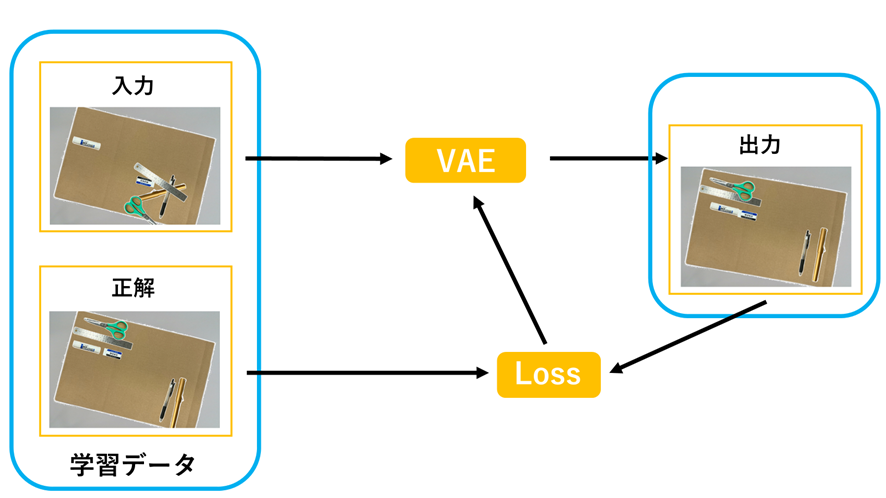
実験では,複数のユーザの片付け方を訓練させ,散らかっている配置に対してより適切な片付いた配置が提案されるかを検証しました.

本研究では物体の位置姿勢に着目しましたが,私達が実際に片付けを行う際に,外観特徴(形状や模様)が似た物体を集めて配置することがあります.よって,画像のテクスチャを用いた片付けの実装に今後取り組みたいと思います.
2.領域分割モデルと局所特徴の照合を用いた画像トラッキング精度の向上
現在のリアルタイム画像トラッキングであるBoT-SORTというモジュールでは,追跡物体と検出物体のID割り当てを以下の指標に基づき行います.
- CNNを用いて抽出したBBox内部画像特徴ベクトルのコサイン類似度
- カルマンフィルタによって予測された追跡BBoxと検出BBoxのIoUスコア
しかし,ID割り当てや位置予測は常に正しく行われるとは限りません.以下の写真のように,静止している物体が隠蔽されるとその位置が誤予測されたり,物体同士が交錯するとIDが入れ替わり得ます.


本研究では,隠蔽・交錯発生時にもID割り当てが正しく行われるようにすることを目的としました.1つ目の事象の発生を抑制するために,領域分割モデルを用いて物体が他物体に隠蔽されたかの判定・動きの分類をし,速度予測モデルを切り替える機能を実装しました.また,2つ目の事象の発生を抑制するために,領域分割モデルとSIFT特徴の照合を用いて,物体の細かい特徴を優先したID割り当て機能を実装しました.なお,実装した機能は全てBoT-SORTに搭載しました.
隠蔽判定・動き分類について
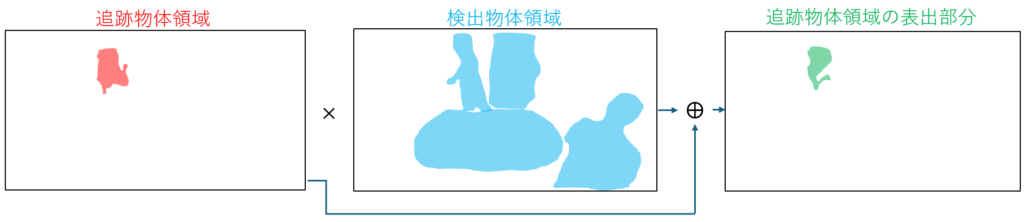
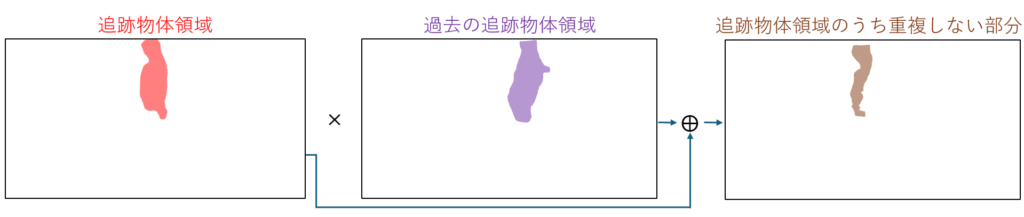
まず,領域分割によって取得した物体領域を重ね合わせることで追跡物体の隠蔽を判定します.「追跡物体領域のうち,現フレームで他物体に隠されていない」とされる部分を抽出し,隠蔽されたかを判定します.隠蔽されたと判定された物体に対し動きの分類を行います.静止していたと分類された物体の速度予測モデルを切り替え,予測された物体の位置情報が更新されないされないようにします.
SIFT特徴を用いたID割り当てについて
追跡物体と検出物体の持つSIFT特徴の照合を行い,その結果を用いてID割り当てを行います.物体自体の持つ細かい特徴の照合を用いることで,背景情報を除去した外観特徴の比較をすることができます.
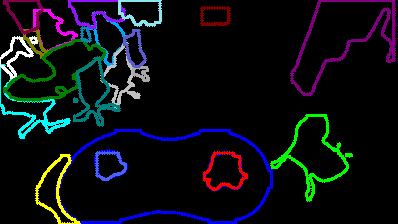
下の写真では,各物体領域を青くマスクしており,赤い円でSIFT特徴が描かれています.物体領域内に属するSIFT特徴のみが描かれていることが分かります.右の写真では,照合が取れた特徴同士を緑線で結んでいます.検出物体のうち追跡物体に相当する物体が持っている特徴と,追跡物体の持つ特徴が多く照合していることが分かります.このSIFT特徴の照合を用いてID割り当てを行う機能を実装しました.

実験
人間同士が交錯する動画を複数撮影し,BoT-SORT及び本研究で実装した機能を搭載したBoT-SORTに入力して交錯の前後でID割り当てが正しく行われた割合を比較しました.
左はあるシーンに対するBoT-SORTの追跡結果を,右は同じシーンに対する,本研究で実装した機能を搭載したBoT-SORTの追跡結果を示しています.左ではID44と47の人間が交錯しIDが入れ替わりますが,右ではID58と62の人間が交錯してもIDが入れ替わりませんでした.
しかし,ID割り当てが正しく行われた割合を全体的に比較すると,本提案手法がBoT-SORTを下回る結果となりました.その原因として,隠蔽・交錯時の領域分割が不安定であることが挙げられます.複数物体が合体した領域,もしくは他物体の一部を含む領域が「1つの物体の領域」として検出された結果,複数物体のSIFT特徴が「1つの物体の特徴」として登録されていることが分かりました.このように領域分割が不安定であることを考慮したSIFT特徴の選別や照合を基にIDを割り当てるアルゴリズムを考案することが今後の課題と考えています.

3.ジェスチャープロンプトを用いた一般物体検出: 事前学習済みオープンボキャブラリ物体検出器の活用
近年の機械学習の発展に伴い,物体検出モデルにも様々なモデルが登場しており,事前学習済みの固定数クラスの物体を検出する,YOLOのようなモデルに対し,OWL-ViTのようなクエリベースの物体検出モデルが存在します.クエリベースの物体検出モデルにおけるクエリには通常,テキストや物体の見えなどを用いますが,形や程度を表すことが難しく,より柔軟な表現が可能なクエリを用いた物体検出の実現が求められています.本研究では,そのような物体検出実現への第一歩として,ハンドジェスチャーをクエリとした一般物体検出を実現します.
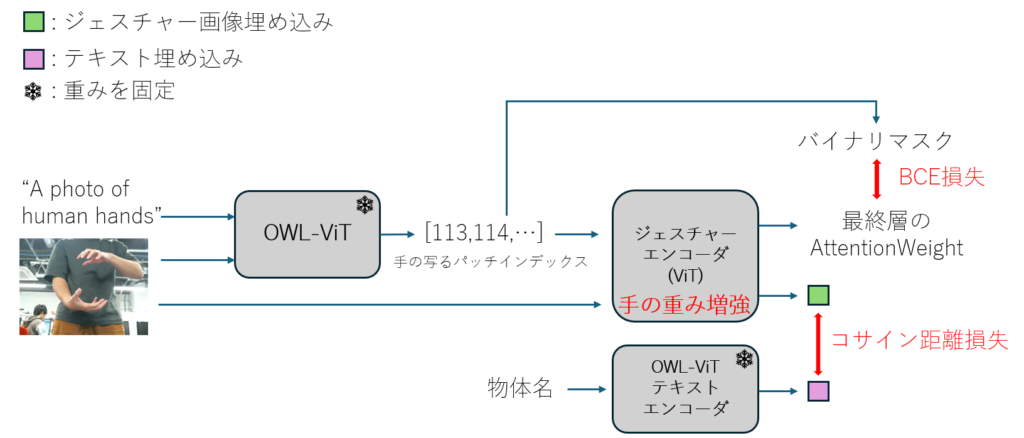
本研究では,物体検出の基盤として事前学習済みのOWL-ViTを採用しています.訓練時のモデル構造は上図のようになり,テキストエンコーダの出力に類似した埋め込みを生成するようにジェスチャー画像エンコーダを訓練します.加えて,ジェスチャー画像における背景や距離の変化に対するロバスト性を向上させるため,ジェスチャー画像エンコーダの最終層にて,手領域の重みを増強するように誘導する損失関数を定義します.推論時にはOWL-ViTのテキストエンコーダを,訓練済みのジェスチャー画像エンコーダに置き換えることで,ジェスチャー画像を入力とした物体検出を実現します.
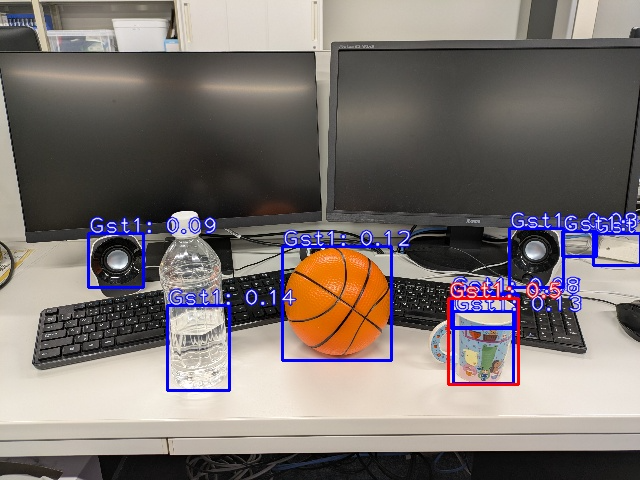
以下の画像は実際にジェスチャー画像を入力とした物体検出を行った結果であり,ジェスチャーに対して適切な物体領域のスコアが顕著に高くなっていることを示しています.

4.顔認識と人物追跡の統合による新規人物の自動登録とRe-id
近年, イベント会場での入退場管理や店舗での顧客管理など幅広い分野でコンピュータを用いた個人識別システムが利用されています. しかし, 一般的なシステムは事前にデータベースなどに登録しておいた人間を映像の中から識別することのみしかできず, 登録していない人物を新しくデータベースに登録する機能が実装されていません. そこで, 本研究では既存システムに顔認識の機能を組み込むことで顔認識と人物追跡の情報を組み合わせて新規人物の自動登録ができるのではないかと考えました.
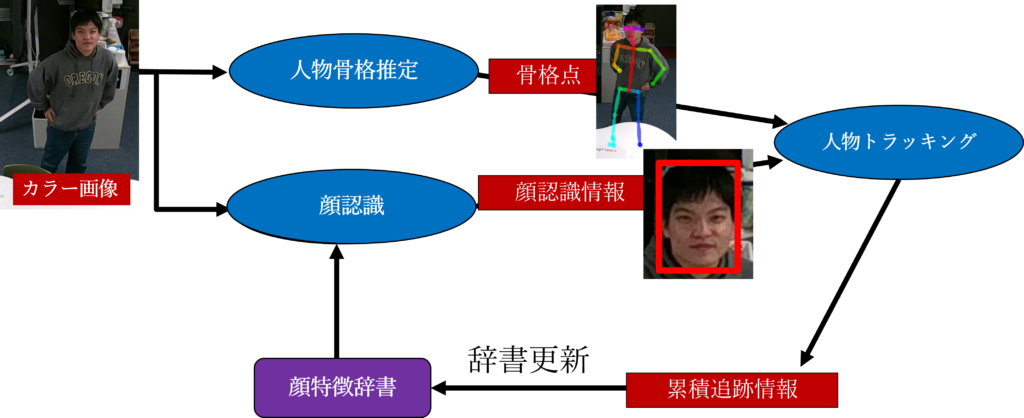
本システムでは人物追跡と顔認識の結果から作り出した複数の顔特徴のペア(累積追跡情報)を用いて定期的に顔認識に用いる辞書を更新することで新規人物の自動登録を実装しました.
以下の動画は実際に事前に登録していたuser_2が認識される様子と新規人物がuser_new4として登録される様子を示したものです. なお, 初めは赤くユーザ名が表示されていて, 確信を持ったタイミングでユーザ名の表記が緑色に変わります.