背景と目的
近年では産業目的だけでなく、人の生活に密接に関わり、人間の生活をサポートすることを目的としたロボットの研究が進められています。そういったロボットは実空間の物体の位置を把握し、適切な行動を行う必要があります。
本研究室ではロボットに画像認識などを用いてロボットに適切な行動を選択できるように研究を行っています。

研究内容
【1】物体把持方法の想起
人の簡単な指示に応じてロボットが自動的に複雑な動作を生成して物体を把持するためには、1つのオブジェクトに対して複数の把持方法の候補の中から適応的に推定することが重要です。
そこで、オブジェクトが写った画像から把持位置や手の形状の候補を特徴別に想起する方法について研究を進めています。

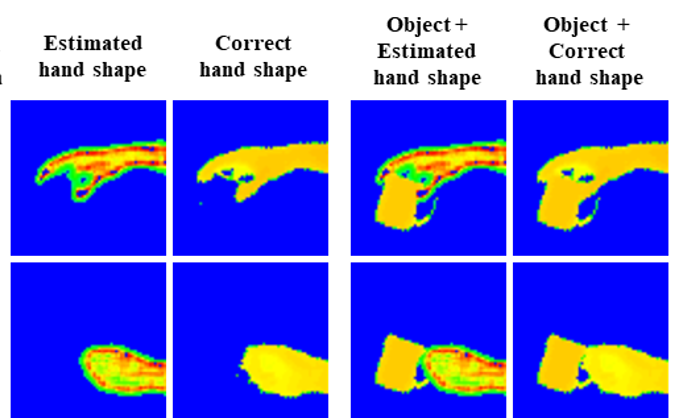
【2】Transform Invariant Auto-encoderを用いた人間の把持方法の模倣
Auto-Encoderは次元削減方式の一種で入力ベクトルを重要な情報を表す記述子へマッピングすることができます。しかし、空間的にシフトした画像はシフトしていない画像とは異なる記述子へマッピングされてしまいます。
そこでシフト情報を分離し、画像内のパターン情報をマッピングすることができるTransform Invariant Auto-encoderを提案しました。これを用いると前処理なしで人間の手の画像から形状情報を抽出することができます。

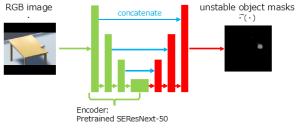
【3】深層学習を用いた家庭内環境における不安定物体の推定
机の上に物体が存在するというシチュエーション下にてその物体が落ちそうかそうでないかを推定する研究を行いました。学習データをUnity上でシミュレーションして作っているため、物体の エネルギー変位などを教師信号として用いることができています。
【4】人間共存環境におけるアームロボットの回避行動
ロボットが人間のいる空間で行動する場合、人間は独立して動くため、ロボットは人間の行動に干渉しないように行動しなくてなりません。
この研究ではSciurus17というヒューマノイドロボットを用いて、ロボットのカメラに映る人間を障害物を認識し、人間を避けるように行動することを目的としています。



【5】姿勢による移動性の違いを考慮した人物の位置推定
ロボットはカメラで観測している物体の位置の変化は認識できますが、観測範囲外ではその変化を認識できません。そこで過去の観測から現在の物体の位置推定を研究します。
この研究ではRealsenseという深度カメラを用いて人間の骨格推定を行い、人間の立ち姿勢と座姿勢を把握します。そして、姿勢による移動性の違いを考慮した上で、過去の人間の姿勢から、人間の現在位置の推定を行います。


上図の左側はカメラの映像、右側の赤と黄緑の点群はロボットが観測している人間の位置を示す。カメラが観測できない位置に人が移動すると、観測できなくなる直前の人間の姿勢から、現在の人間の位置を推定する。推定位置まで点群の位置が移動する。
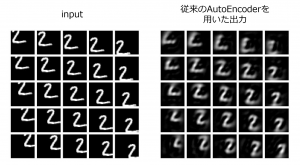
【6】部分観測から復元した 全体像の曖昧さを反映する 記述子空間の設計手法
視覚的想像力の実現のために、深層学習を用いて画像内のどの物体が不安定であるかを推定します。
そのために、画像内の物体に外力を加えたときに変化する位置エネルギーの推定を深層学習を用いて試みます。
不安定な状態の物体の画像と力の大きさと向きをCNN(畳み込みニューラルネットワーク)に入力します。
すると、不安定な物体がどれであるかがわかります。
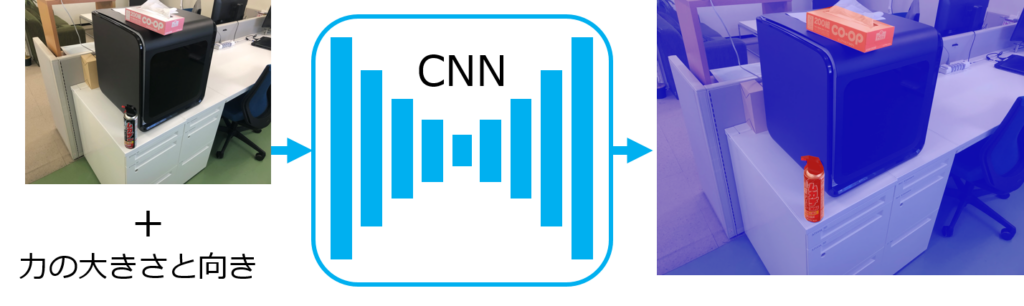
しかし、ある視点からの情報では物理的な情報を取得することに限界があります。
そこで、人間のように複数視点の情報を組み合わせて観測の不完全さを考慮した曖昧性を表現することを試みています。
つまり、1視点からだけではなく、複数視点からの情報を組み合わせることでより良い認識を試みています。
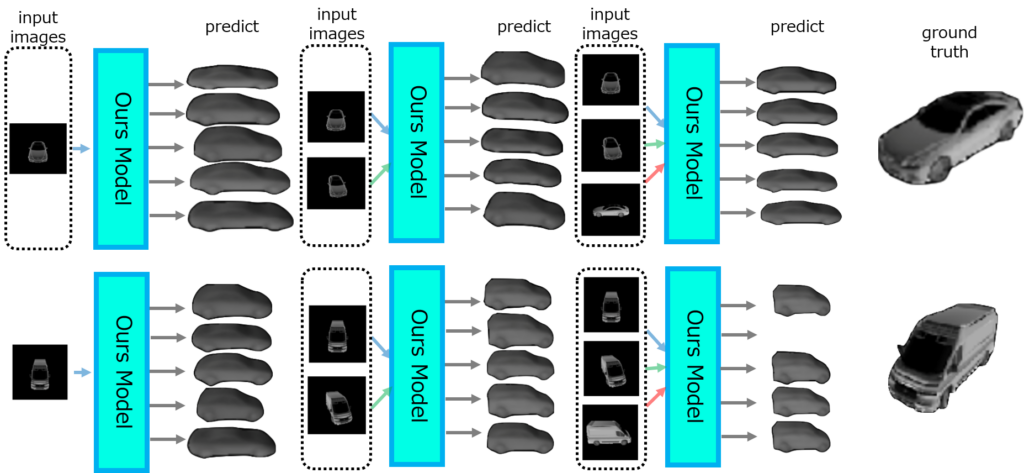
ShapeNet[1]という3D物体のデータセットの中から車についてのデータを入力として提案手法で予測を行いました。
複数視点からの情報を与えることで予測の物体の形が真値に近づいていることが確認できます。
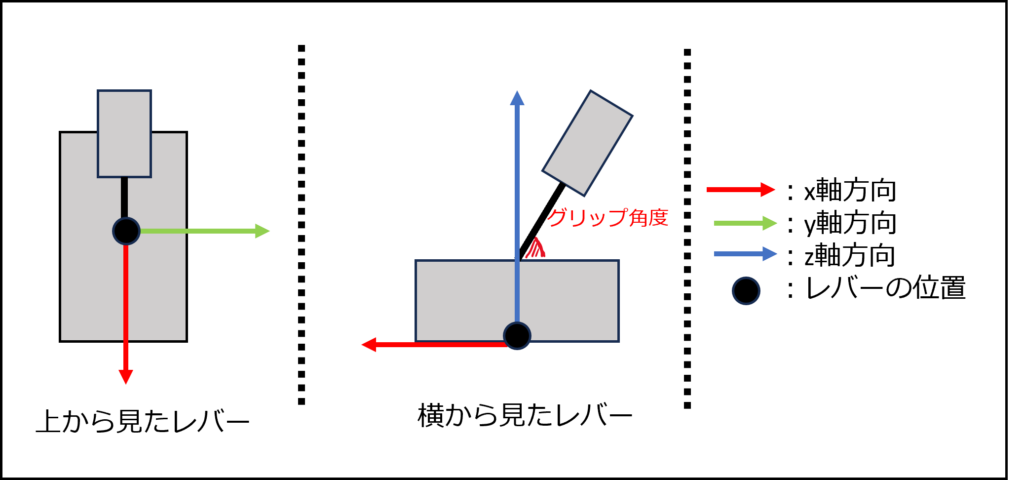
【7】TRGAILに基づく多段レバースイッチの視触覚統合制御
世の中には力の変化を伴う動作があり、それらの動作をロボットが学習するには、視覚・触覚の情報を用いて学習を行う必要があります。そこで、操作時に複数の段階で抵抗が発生する多段レバースイッチを用いて、レバーの操作行動の学習を行います。
視覚情報ではレバーの位置、向き、グリップ角度を画像検知モデルにより獲得します。
触覚情報はロボット内部のモータートルクから、手先の力を獲得します。
これらの情報を基に模倣学習手法・TRGAILを用いて学習を行います。

今回は段数が2段である多段レバーを学習させ、レバーを倒しきる行動を獲得させることが出来た。また、段の位置と数を変更し、段数を3段に変更した場合も倒しきる行動が確認できた。現在はレバーを倒しきる行動のみしか行うことが出来ないため、今後はレバーを特定の段数乗り越えたところで止める行動をとることが出来るモデルの構築を目指す。
【8】不規則移動物体の追従及び捕獲のためのROS2 MoveIt2の拡張
分散協調システムのフレームワークであるROSにおいて,ロボットアームの軌道計画を作成するパッケージであるMoveItでは,動的な環境におけるタスクを想定していなかったため,アームの軌道を動作中に変更することができなかった.本研究では,動的な環境に適応する必要があるタスクとして,移動するボールを追従することを設定した.
本システムでは,位置制御によりアームを制御している.エンドエフェクタが取るべき位置姿勢を連続的に変更することにより,ボールの追従を実現した.一回のゴール変更の所要時間が0.2ms程度と非常に高速に動作することが確認できた.また,ROSノードとして実装したため再利用性に優れている.
ROS2 で実装されたHybrid Planningの拡張を行うことで,ROS上においてロボットアームは,環境に適応的な振る舞いを獲得することができた.
本実験ではrealsenseという深度カメラを用いており,RGBイメージに対するYOLOXによる物体検出と深度情報の組み合わせにより,ボールの3次元位置を特定する.ここで得られた3次元座標にロボットアームの手先が向かうよう指示を出し続ける.

上記のボール追従をより遅延なく実行させるために,物体の検出位置から未来の座標位置を予測して,予測した位置をゴール地点とする軌道生成を行うよう改変を加えた.また把持を行う前段階として,ボールの追従を行いながらボールめがけて下降を行う動作を実装した.

【9】二軸モータハンドを用いた積層食器の引き出しの実現
本研究では,外食産業における労働力不足の課題を背景に,積層された食器の自動ハンドリング手法に着目し,二軸モータを用いたモータハンドによる食器の引き出し動作の解析と実験を行った.積層食器の引き出し解析結果と引き出し実験結果から類似した傾向を確認することができた.
二軸モータハンドを用いた積層食器の引き出しの解析では,食器の引き出しモデルを考え,力のつり合い式から引き出しに必要な条件を得る.
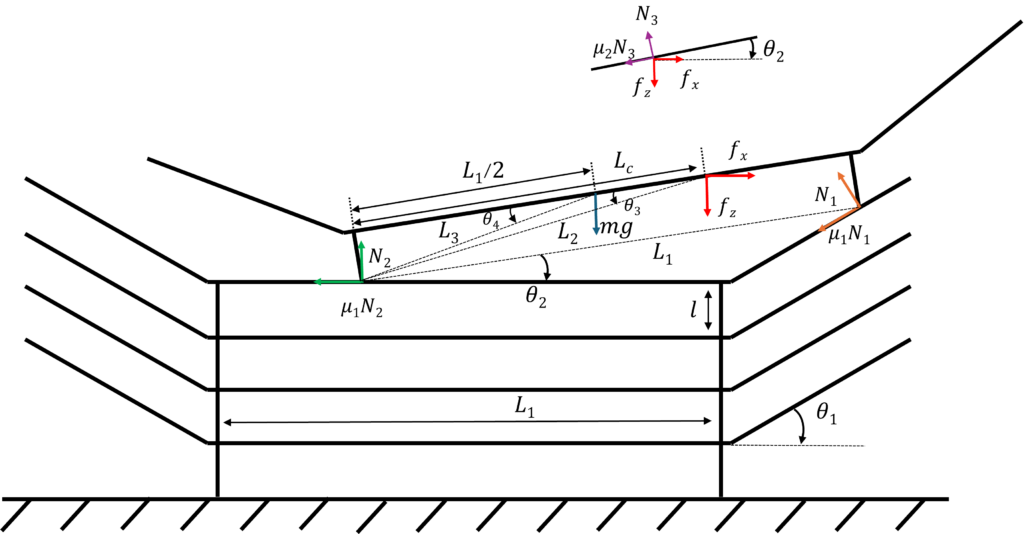
そして,モータハンドを用いた積層食器の引き出し実験から実際に食器を動かすために必要な力を計測する.

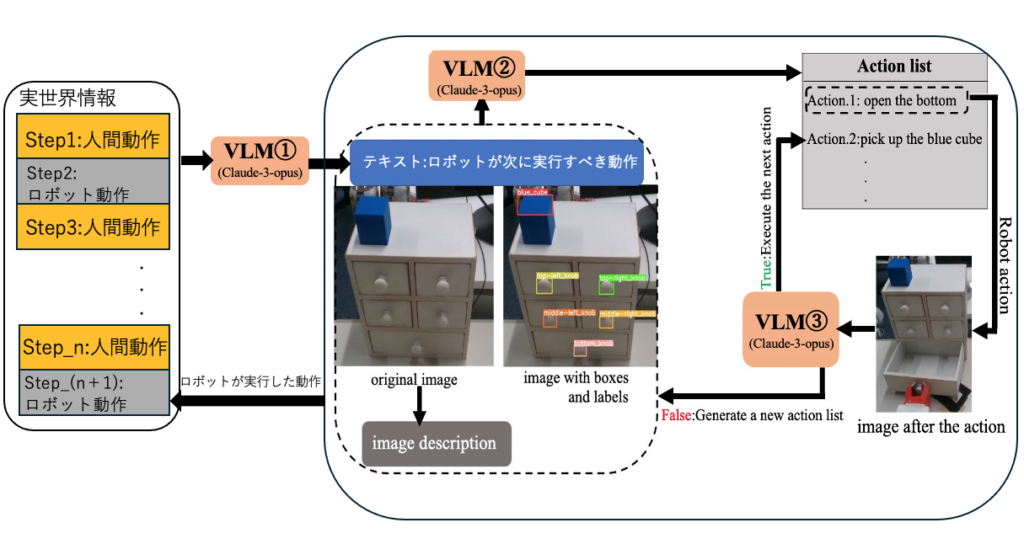
【10】VLM と視覚プロンプトを用いた部分動作の成否推論に基づくロボット動作列生成及び人機協調
本研究では、視覚プロンプトと視覚言語モデル( VLMs )を活用し、人間の意図を推定しつつ、人間とロボットの協調作業を通じて共通タスクを達成するための実行可能なロボット行動シーケンスを生成する新たな手法を提案する。本手法は、一連の注釈(ボックスやラベル)を利用して VLM の環境理解を強化し、現場の環境変化に応じて人間の意図を動的に推測することで、共通目標を達成するための最適なロボット行動シーケンスを生成する。また、行動の失敗や外部からの干渉が発生した場合には、 VLM の分析により、新しいシーケンスを再生成する仕組みを備えている。さらに、本研究で提案する技術は、プロンプトを多様なタスクに対応可能な汎用モジュールとして設計することで、効率性と適応性に優れたロボット行動計画を実現する新たなアプローチを提供する。
キューブを対象として、「put blue cube into bottom drawer」指示をロボットに与え、実験結果は以下の図に示す。

キューブを対象として、「青いキューブを一番下の引き出し内に置く」指示をロボットに与え、実験結果は以下の図に示す。
まず、ロボットは引き出しを掴み、開く動作を実行した。しかし、ロボットが引き出しを開けた直後に人間が干渉し、それを閉じるという操作を行った。この結果、ロボットは動作の失敗を検出し、再度引き出しを開く動作を実行した。
次に、ロボットがキューブを掴みに行く際、人間がキューブの位置を移動させるという干渉を行った。これにより、ロボットは再び動作の失敗を判断し、現在の環境状況を基に新たな動作シーケンスを生成した。その後、ロボットはキューブを掴み直し、底部の引き出し内に配置することで、指示された「 put blue cube into bottom drawer 」のタスクを完了した。