Background and Purpose
We consider that it’s hard to convert one person’s voice to another due to human himself, because of the limits of our body structure.
So, we tried to make a deep learning model for voice conversion, to break that limit.
This technique can be used in making subtitles for movie, or helping people who have lost their voice to talk.
Therefore, we are currently conducting the research of voice conversion.
Experiments
Singing Voice Conversion(SVC)
Converting a song into a another singer’s voice while maintaining the lyrics and tune.
Results
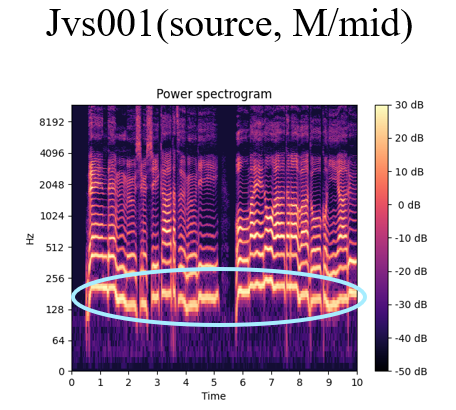
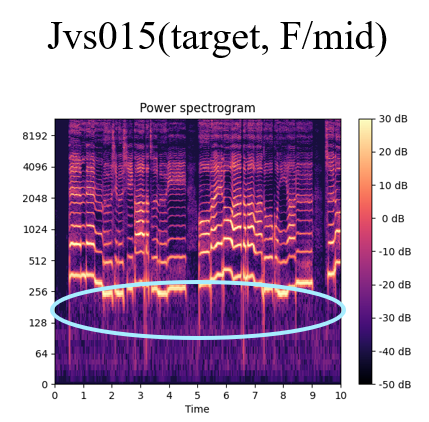
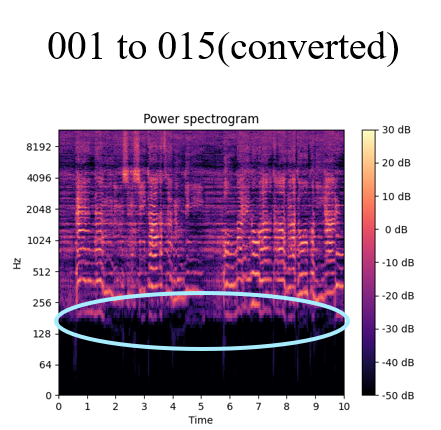
While the source data of a male’s voice(fig.1) contains the typical 128Hz ~ 256Hz of low frequency power, the converted data(fig.3) shows that the low frequency power is deleted due to voice converting. In this case, ground truth is the power spectrogram showing in fig.2.